高通量测序原理及其发展简介
本文核心词:
一.高通量测序简介
1.什么是高通量测序
高通量测序技术也被称作二代测序技术(Next Generation Sequencing, NGS),这是相对一代测序技术(Sanger Sequencing)而言的,同时由于高通量测序的出现使得我们能对一个物种的基因组和转录组进行全面、细致的分析成为可能,所以又被称为深度测序(deep sequencing)。高通量测序技术以能一次并行对几十万到几百万条DNA分子进行序列测定和一般读长较短等为标志,通过读取多个短DNA 片段,拼接成完整的序列信息。与一代测序Sanger法相比,高通量测序技术在处理大规模样品时具有显著的优势,在测序速度及测序通量上具有无可取代的地位,是目前组学研究中的核心技术。

那么一代测序和二代测序有何区别呢?我们先来看看下面这一张图片:

图1 DNA双脱氧链终止法测序原理详解图
Sanger 测序原理:将基因组 DNA 片断化,然后克隆到质粒载体上,再转化大肠杆菌。对于每个测序反应,挑出单克隆,并纯化质粒 DNA。每个每个循环测序反应含有所有四种脱氧核苷酸三磷酸(dNTP)使之扩增,并混入限量的一种不同的双脱氧核苷三磷酸(ddNTP)使之终止。由于ddNTP的2’和3’都不含羟基,其在DNA的合成过程中不能形成磷酸二酯键,因此可以用来中断DNA合成反应,在4个DNA合成反应体系中分别加入一定比例带有放射性同位素标记的ddNTP(分为:ddATP,ddCTP,ddGTP和ddTTP),使延长的寡聚核苷酸选择性地在G、A、T或C处终止,并产生荧光标记,最终得到一组长几百至几千碱基的链终止产物,它们具有共同的起始点,但终止在不同的的核苷酸上。通过凝胶电泳和放射自显影后可以根据电泳带的位置确定待测分子的DNA序列。

图2 Sanger 测序与二代测序的流程比较
第一代测序技术的主要特点是测序读长可达1000bp,准确性高达99.999%,但其测序成本高,通量低等方面的缺点,严重影响了其真正大规模的应用。因而第一代测序技术并不是最理想的测序方法。经过不断的技术开发和改进,以Roche公司的454技术、illumina公司的Solexa,Hiseq技术和ABI公司的Solid技术为标记的第二代测序技术诞生了。第二代测序技术大大降低了测序成本的同时,还大幅提高了测序速度,并且保持了高准确性,以前完成一个人类基因组的测序需要3年时间,而使用二代测序技术则仅仅需要1周,但在序列读长方面比起第一代测序技术则要短很多。

图3 测序仪发展(一代与二代测序仪图片展示)
小知识:第一代DNA测序技术(又称Sanger测序)在1975年,由Sanger等人开创,并在1977年完成第一个基因组序列(噬菌体X174),全长5375个碱基。
2.高通量测序发展史(1)人类基因组计划(human genome project, HGP)
在介绍高通量测序发展之前,需要先为大家介绍一个人类发展史上的一项重要创举——人类基因组计划(human genome project, HGP)。HGP的完成对测序技术的推动作用意义重大。
HGP是由美国科学家于1985年率先提出,于1990年正式启动的,是一项规模宏大,跨国、跨学科的科学探索工程。其宗旨在于测定组成人类染色体(指单倍体)中所包含的30亿个碱基对组成的核苷酸序列,从而绘制人类基因组图谱,并且辨识其载有的基因及其序列,达到破译人类遗传信息的最终目的。HGP的主要任务是人类的DNA测序,包括遗传图谱、物理图谱、序列图谱和转录图谱的绘制。美国、英国、法国、德国、日本和中国科学家共同参与了这一预算达30亿美元的人类基因组计划。按照这个计划的设想,在2005年,要把人体内约2.5万个基因的密码全部解开,同时绘制出人类基因的图谱。到2001年2月12日,科学家首次公布“人类基因组图谱”草图;2003年4月15日,国际人类基因组组织正式宣布,人类基因组计划全部完成。
选择人类的基因组进行研究是因为人类是在“进化”历程上最高级的生物,对它的研究有助于认识自身、掌握生老病死规律、疾病的诊断和治疗、了解生命的起源。测出人类基因组DNA的30亿个碱基对的序列,发现所有人类基因,找出它们在染色体上的位置,破译人类全部遗传信息。在人类基因组计划中,还包括对五种生物基因组的研究:大肠杆菌、酵母、线虫、果蝇和小鼠,称之为人类的五种“模式生物”。
HGP是人类为了探索自身的奥秘所迈出的重要一步,是继曼哈顿计划和阿波罗登月计划之后,人类科学史上的又一个伟大工程。 HGP在研究人类过程中建立起来的策略、思想与技术,构成了生命科学领域新的学科——基因组学,可以用于研究微生物、植物及其他动物。它是人类自然科学史上最伟大的创举之一。

图4 HGP时间表
(2)高通量测序的发展
自2003年人类基因组计划完成之后,测序技术发展迅猛,多种测序原理产品在市场上出现,接受市场的检验。测序读长不断加长、通量不断提升、时间不断缩短,促进测序成本快速下降,大量基因组序列被破译,测序物种数量和物种多样性与日俱增。
“基因科技造福人类”, NGS测序仪的出现具有非凡意义,测序技术的发展自此势如破竹、高歌猛进。最初个人全基因组测序费用高达令人咋舌的1亿美金;发展到2008年,一个100Gb数据量的人基因组只需几十万美金,降幅达99%;到2014年,只需要1000美金左右,仅相当于1亿美金的五万分之一;时至今日,100美元人类基因组已成为现实!
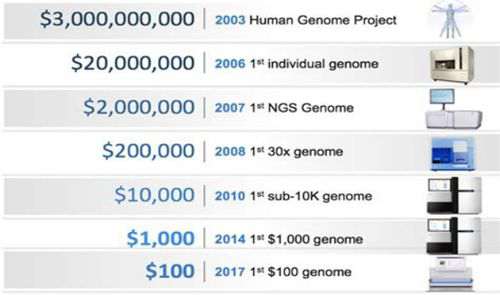
图5 高通量测序成本变化
第一台NGS测序仪是在2005年出现的,454公司推出第一个基于焦磷酸测序原理的高通量基因组测序系统——Genome Sequencer 20 System,这是核酸测序技术发展史上里程碑式的事件。随后,Roche公司收购了454公司,并在2006年推出了更新的Roche 454 GS FLX测序系统。
2006年,Solexa公司也推出了自己的NGS系统——Genome Analyzer,简称GA。这套基于DNA簇(DNA cluster)、桥式PCR(Bridge PCR)和可逆阻断(Reversible terminator)等核心技术的系统具有高通量、低错误率、低成本、应用范围广等优点。2007年,Illumina公司收购了Solexa,使GA得以商品化。
在上述两家公司之前,测序市场的垄断地位一直由美国应用生物系统公司(ABI)牢牢掌控。但是,2005年454推出了FLX焦磷酸测序平台,ABI的领先地位被撼动,于是,ABI迅速收购了一家测序公司——Agencourt Personal Genomics,并在2007年底推出了SOLiD 新一代测序平台。
与前面三家相比,Ion Torrent起步较晚,Ion Torrent是由Jonathan Rothberg于2007创办(一个传奇人物,1999年创建454,2007年卖给Roche),并于2010年推出首款Ion PGM测序仪,同年Life Technologies收购了Ion Torrent, 此时Ion Torrent已经开始小有名气。2012年推出Ion Proton测序仪,随后2013年Life Tech又被Thermo fisher收购,并于2015年推出Ion S5XL测序仪。
小插曲:生物界传奇人物Jonathan Rothberg小故事,为什么Jonathan Rothberg执著于测序仪开发呢?事情是这样的,Jonathan Rothberg的儿子一出生,就被马上送进婴儿特别护理病房接受治疗,那时的 Rothberg 都不知道发生了什么,以为孩子患有某种先天性的疾病,整天都在担心自己的孩子。于是,他想要是有一种能提前了解孩子遗传物质的技术就好了,于是他下定决心要开发一种快速便宜的测序技术来解决这个问题。若干年后,也就是2005 年,Rothberg 的梦想终于实现了。454 生命科学等研究人员于 7 月在《 Nature 》杂志上发表了一篇题为“Genome sequencing in microfabricated high-density picoliter reactors ”的文章,介绍了一种边合成边测序(sequencingby synthesis)的技术,比传统的 Sanger 测序快 100 倍。

图6 测序仪的发展史
测序市场在2010年前后形成了Roche 454、Illumina Solexa和ABI SOLiD三足鼎立的局面。但是后续SOLiD系统通量难以提升,且读长短、成本高,现已退出了历史舞台;454技术因其成本较高,市场接受度不高,导致生命科学测序业务被关闭。而Complete Genomics公司的Black Bird测序仪、Helicos公司Heliscope测序仪等,由于自身的短板导致市场份额逐渐缩小,独留Illumina“一人独霸天下”。
表1 不同测序公司采取的测序原理列表

3.高通量测序平台及其性能参数介绍
Roche 454、Illumina Solexa和ABI SOLiD为主的三个测序平台,目前最主流的二代测序平台是 Illumina 所生产的测序仪,包括 MiSeq 系列、 HiSeq 系列、 NextSeq 系列等。另外的还包括罗氏公司的 454 测序仪(目前已关闭)、华大基因的 BGI-CG 测序仪以及 Life Technology(已被 Thermo Fisher 收购)的 Ion Torrent 等。

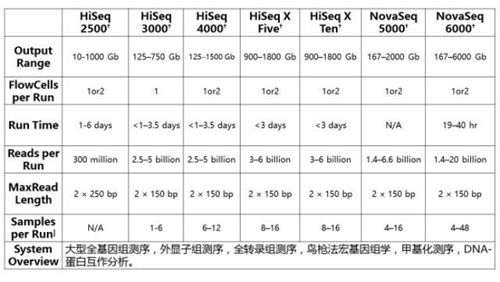
图7 Illumina测序仪性能参数
联川生物公司目前所采用的测序仪为Illumina Hiseq、MiSeq、NextSeq及NovaSeq,其性能简介如下:
MiSeq系统可实现广泛的测序应用,它能够自动生成双端读取,进行2500万条测序read和2 x 300 bp的读长,每次运行可产生15 Gb数据。它使用的文库制备试剂盒是为多个应用而优化的,包括靶向基因、小型基因组、扩增子测序以及16S元基因组等。
HiSeq 2500系统特有两种运行模式,快速运行和高产出运行模式,能够同时处理一个或两个流动槽。这提供了一个灵活、可扩展的平台,支持最广泛的测序应用和研究规模。可根据项目需求,在快速运行和高产出模式中选择。HiSeq 3000/HiSeq 4000测序系统是基于HiSeq 2500系统的成熟性能,利用超高通量HiSeq X系统的图案化流动槽技术,提供出色的测序速度和性能。HiSeq 3000/HiSeq 4000提供了高覆盖度、快速周转和处理各种样本类型的灵活性,为大规模的基因组实验室提供了多个应用的解决方案。
NextSeq500主要用于子公司捕获产品,用于靶向基因测序(全外、扩增子等)。NextSeq系列测序仪凭借可调整的产量和很高的数据质量,可以提供全基因组、转录组和靶向重测序实验。
除以上常规通量的平台外,Illumina于2017年初推出了可扩展的全新测序架构,由两台仪器组成:NovaSeq 5000和NovaSeq 6000。这两个系统之间的差异在于它们运行的流动槽。NovaSeq 5000可运行S1和S2流动槽,而NovaSeq 6000可运行S1、S2、S3和S4四种不同的流动槽。S2格式的流动槽最先推出,而S1、S3和S4流动槽于2017年的晚些时候推出。根据Illumina网站上的系统参数,NovaSeq测序系统的产量范围在167 Gb至6 Tb,每次运行的reads数量在16-200亿。以S2流动槽为例,它每次运行最多可测序16个人类基因组,或132个外显子组或转录组。
从以上各平台的介绍来看,Illumina产出的测序仪数据通量越来越高,NovaSeq6000的通量已达6000Gb,与高通量测序发展之初的几Gb、几十Gb相比,通量提高了成百上千倍。
4.高通量测序的过程及原理介绍
高通量测序技术的一般过程是将DNA(或cDNA)随机片段化,加上接头序列,制备用于上机测序的文库,通过对文库中数以万计的克隆(colony)进行延伸反应,检测对应的信号获取序列信息,最终通过数据分析来挖掘序列中的科学问题。几种不同测序平台的原理及步骤如下:
(1)Roche 454 平台
Roche 454测序系统是第一个商业化运营二代测序技术的平台,也是首选将焦磷酸测序应用在测序技术上的平台。测序原理如下:
1)DNA文库制备
454测序系统的文件构建方式和illumina的不同,它是利用喷雾法将待测DNA打断成300-800bp长的小片段,并在片段两端加上不同的接头,或将待测DNA变性后用杂交引物进行PCR扩增,连接载体,构建单链DNA文库。
(2)Emulsion PCR (乳液PCR,其实是一个注水到油的独特过程)
454当然DNA扩增过程也和illumina的截然不同,它将这些单链DNA结合在水油包被的直径约28um的磁珠上,并在其上面孵育、退火。
乳液PCR最大的特点是可以形成数目庞大的独立反应空间以进行DNA扩增。其关键技术是“注水到油”(水包油),基本过程是在PCR反应前,将包含PCR所有反应成分的水溶液注入到高速旋转的矿物油表面,水溶液瞬间形成无数个被矿物油包裹的小水滴。这些小水滴就构成了独立的PCR反应空间。理想状态下,每个小水滴只含一个DNA模板和一个磁珠。
这些被小水滴包被的磁珠表面含有与接头互补的DNA序列,因此这些单链DNA序列能够特异地结合在磁珠上。同时孵育体系中含有PCR反应试剂,所以保证了每个与磁珠结合的小片段都能独立进行PCR扩增,并且扩增产物仍可以结合到磁珠上。当反应完成后,可以破坏孵育体系并将带有DNA的磁珠富集下来。进过扩增,每个小片段都将被扩增约100万倍,从而达到下一步测序所要求的DNA量。
(3)焦磷酸测序
测序前需要先用一种聚合酶和单链结合蛋白处理带有DNA的磁珠,接着将磁珠放在一种PTP平板上。这种平板上特制有许多直径约为44um的小孔,每个小孔仅能容纳一个磁珠,通过这种方法来固定每个磁珠的位置,以便检测接下来的测序反应过程。
测序方法采用焦磷酸测序法,将一种比PTP板上小孔直径更小的磁珠放入小孔中,启动测序反应。测序反应以磁珠上大量扩增出的单链DNA为模板,每次反应加入一种dNTP进行合成反应。如果dNTP能与待测序列配对,则会在合成后释放焦磷酸基团。释放的焦磷酸基团会与反应体系中的ATP硫酸化学酶反应生成ATP。生成的ATP和荧光素酶共同氧化使测序反应中的荧光素分子并发出荧光,同时由PTP板另一侧的CCD照相机记录,最后通过计算机进行光信号处理而获得最终的测序结果。由于每一种dNTP在反应中产生的荧光颜色不同,因此可以根据荧光的颜色来判断被测分子的序列。反应结束后,游离的dNTP会在双磷酸酶的作用下降解ATP,从而导致荧光淬灭,以便使测序反应进入下一个循环。
由于454测序技术中,每个测序反应都在PTP板上独立的小孔中进行,因而能大大降低相互间的干扰和测序偏差。454技术最大的优势在于其能获得较长的测序读长,当前454技术的平均读长可达400bp,并且454技术和illumina的Solexa和Hiseq技术不同,它最主要的一个缺点是无法准确测量同聚物的长度,如当序列中存在类似于PolyA的情况时,测序反应会一次加入多个T,而所加入的T的个数只能通过荧光强度推测获得,这就有可能导致结果不准确。也正是由于这一原因,454技术会在测序过程中引入插入和缺失的测序错误。



图8 Roche 454 焦磷酸测序原理
(2)Illumina Solexa 平台
Illumina公司的Solexa和Hiseq应该说是目前全球使用量最大的第二代测序机器,这两个系列的技术核心原理是相同的,都是采用边合成边测序的方法,它的测序过程主要分为以下4步:

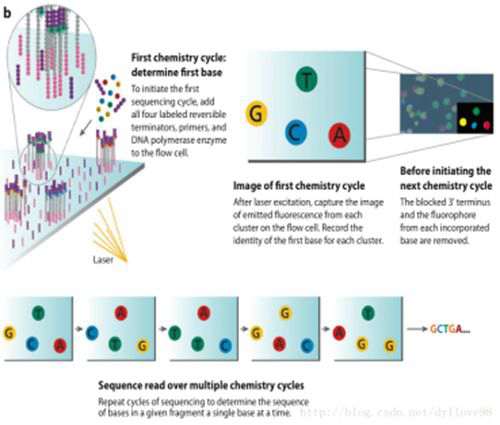
图9 Illumina Solexa测序原理
Illumina Solexa原理:桥式PCR+4色荧光可逆终止+激光扫描成像
① DNA文库制备——超声打断加接头
利用超声波把待测的DNA样本打断成小片段,目前除了组装之外和一些其他的特殊要求之外,主要是打断成200-500bp长的序列片段,并在这些小片段的两端添加上不同的接头,构建出单链DNA文库。
② Flowcell——吸附流动DNA片段
Flowcell是用于吸附流动DNA片段的槽道,当文库建好后,这些文库中的DNA在通过flowcell的时候会随机附着在flowcell表面的channel上。每个Flowcell有8个channel,每个channel的表面都附有很多接头,这些接头能和建库过程中加在DNA片段两端的接头相互配对(这就是为什么flowcell能吸附建库后的DNA的原因),并能支持DNA在其表面进行桥式PCR的扩增。这样就形成了数千份相同的单分子簇,被用做测序模板。
③ 桥式PCR扩增与变性——放大信号
桥式PCR以Flowcell表面所固定的接头为模板,进行桥形扩增,如图4.a所示。经过不断的扩增和变性循环,最终每个DNA片段都将在各自的位置上集中成束,每一个束都含有单个DNA模板的很多分拷贝,进行这一过程的目的在于实现将碱基的信号强度放大,以达到测序所需的信号要求。
④ 测序——测序碱基转化为光学信号
测序方法采用边合成边测序的方法。向反应体系中同时添加DNA聚合酶、接头引物和带有碱基特异荧光标记的4中dNTP(如同Sanger测序法)。这些dNTP的3’-OH被化学方法所保护,因而每次只能添加一个dNTP。在dNTP被添加到合成链上后,所有未使用的游离dNTP和DNA聚合酶会被洗脱掉。接着,再加入激发荧光所需的缓冲液,用激光激发荧光信号,并有光学设备完成荧光信号的记录,最后利用计算机分析将光学信号转化为测序碱基。这样荧光信号记录完成后,再加入化学试剂淬灭荧光信号并去除dNTP 3’-OH保护基团,以便能进行下一轮的测序反应。Illumina的这种测序技术每次只添加一个dNTP的特点能够很好的地解决同聚物长度的准确测量问题,它的主要测序错误来源是碱基的替换,目前它的测序错误率在1%-1.5%之间,测序周期以人类基因组重测序为例,30x测序深度大约为1周。
(3)ABI Solid 平台
Solid测序技术是ABI公司于2007年开始投入用于商业测序应用的仪器。它基于连接酶法,即利用DNA连接酶在连接过程之中测序,其流程及原理如下:

图10 ABI Solid测序原理(a)
(1)DNA文库构建
片段打断并在片段两端加上测序接头,连接载体,构建单链DNA文库。
(2)Emulsion PCR
Solid的PCR过程也和454的方法类似,同样采用小水滴emulsion PCR,但这些微珠比起454系统来说则要小得多,只有1um。在扩增的同时对扩增产物的3’端进行修饰,这是为下一步的测序过程作的准备。3’修饰的微珠会被沉积在一块玻片上。在微珠上样的过程中,沉积小室将每张玻片分成1个、4个或8个测序区域(图6-a)。Solid系统最大的优点就是每张玻片能容纳比454更高密度的微珠,在同一系统中轻松实现更高的通量。
(3)连接酶测序
这一步是Solid测序的独特之处。它并没有采用以前测序时所常用的DNA聚合酶,而是采用了连接酶。Solid连接反应的底物是8碱基单链荧光探针混合物,这里将其简单表示为:3’-XXnnnzzz-5’。连接反应中,这些探针按照碱基互补规则与单链DNA模板链配对。探针的5’末端分别标记了CY5、Texas Red、CY3、6-FAM这4种颜色的荧光染料(图6-a)。这个8碱基单链荧光探针中,第1和第2位碱基(XX)上的碱基是确定的,并根据种类的不同在6-8位(zzz)上加上了不同的荧光标记。这是Solid的独特测序法,两个碱基确定一个荧光信号,相当于一次能决定两个碱基。这种测序方法也称之为两碱基测序法。当荧光探针能够与DNA模板链配对而连接上时,就会发出代表第1,2位碱基的荧光信号,图6-a和图6-b中的比色版所表示的是第1,2位碱基的不同组合与荧光颜色的关系。在记录下荧光信号后,通过化学方法在第5和第6位碱基之间进行切割,这样就能移除荧光信号,以便进行下一个位置的测序。不过值得注意的是,通过这种测序方法,每次测序的位置都相差5位。即第一次是第1、2位,第二次是第6、7位……在测到末尾后,要将新合成的链变性,洗脱。接着用引物n-1进行第二轮测序。引物n-1与引物n的区别是,二者在与接头配对的位置上相差一个碱基(图6-a. 8)。也即是,通过引物n-1在引物n的基础上将测序位置往3’端移动一个碱基位置,因而就能测定第0、1位和第5、6位……第二轮测序完成,依此类推,直至第五轮测序,最终可以完成所有位置的碱基测序,并且每个位置的碱基均被检测了两次。该技术的读长在2×50bp,后续序列拼接同样比较复杂。由于双次检测,这一技术的原始测序准确性高达99.94%,而15x覆盖率时的准确性更是达到了99.999%,应该说是目前第二代测序技术中准确性最高的了。但在荧光解码阶段,鉴于其是双碱基确定一个荧光信号,因而一旦发生错误就容易产生连锁的解码错误。

图10 ABI Solid测序原理(b)
(4)Thermo Fisher Scientific Ion Torrent平台
Ion Torrent 测序仪是第一个不需要光学系统的商业测序仪,所采用的技术为半导体测序,通过半导体芯片直接将化学信号转换为数字信号,不同于前面提到的任何测序仪,可以称之为“二代半”测序仪。其测序原理如下:
该技术使用了一种布满小孔的高密度半导体芯片,一个小孔就是一个测序反应池。在半导体芯片的微孔中固定DNA链,随后依次掺入ACGT,当DNA聚合酶把核苷酸聚合到延伸中的DNA链上时,会释放出一个氢离子,反应池中的PH发生改变,位于池下的离子感受器感受到H+离子信号,H+离子信号再直接转化为数字信号,从而读出DNA序列。如果检测的DNA链上有两个相同的碱基,将会检测到电压双倍,芯片则记录两个相同的碱基。

图 12 Ion Torrent测序原理
a. 测序流程图,b.文库制备,c.乳液PCR(前三个步骤与454技术类似),d. 测序过程
Ion Torrent半导体测序技术的发明人也是454测序技术的发明人之一——Jonathan Rothberg,它的文库和样本制备跟454技术很像,甚至可以说就是454的翻版,只是测序过程中不是通过检测焦磷酸荧光显色,而是通过检测H+信号的变化来获得序列碱基信息。由于对对个相同碱基的判读是通过电信号来传导,Ion Torrent平台在聚合酶上进行了优化,新推出的Hi-Q酶聚合反应非常快,它产生的PH值变化的峰更高、更尖、更利于判读,这在很大程度上提高了Ion Torrent测序仪判读Homoploymer区域时的准确性。
Ion Torrent相比于其他测序技术来说,不需要昂贵的物理成像等设备,因此,成本相对来说会低,体积也会比较小,同时操作也要更为简单,速度也相当快速,除了2天文库制作时间,整个上机测序可在2-3.5小时内完成,通量目前是10G左右,但非常适合小基因组和外显子验证的测序。是一种经济、快速、简单、规模可扩展的测序技术,非常适合扩增子测序的革命性技术。
(5)华大基因BGISEQ平台
自2013年华大基因收购Complete Genomics公司后,华大基因致力于开发基因测序平台,还喊出了“打造中国人自己的测序平台”的口号。2014年华大推出BGISEQ-1000、BGISEQ-100两款测序仪,这两款测序仪主要用于基因测序诊断领域,并于2018年1月被申请注销,测序平台已从原有的BGISEQ-100、BGISEQ-1000升级为BGISEQ-50、BGISEQ-500。BGISEQ-500及BGISEQ-50分别于2015、2016年推出,致力于拓展生育健康类测序业务。2017年华大又推出两款测序仪MGISEQ-200和MGISEQ-2000,这两款测序系统充分实现了低成本购机和低成本运行,其广泛的应用领域,包括科学研究、临床医学、农业、公安司法、环境工程等,实现了医疗和科研领域高通量测序系统的全面普及。
目前华大基因在生产中的测序仪共4款。每款测序仪都各具特点,具体的性能参数如下表所示:
表2 华大基因测序仪性能参数

华大基因测序仪的与之前提到的4个测序平台有所区别, BGISEQ/MGISEQ系列测序仪采用先进的联合探针锚定聚合技术(cPAS)和改进的DNA纳米球(DNB)核心测序技术,将DNA分子锚与荧光探针在DNA纳米球上进行聚合,利用高分辨率成像系统对光信号进行采集,并通过对光信号的数字化处理,最终获得待测DNA序列信息。具体步骤如下:
1. DNA提取与片段化
准备样本 → DNA提取 → DNA片段化处理 → DNA片段末端修复
2. DNA片段扩增(纳米球技术DNB)
加接头序列 → 分离出单股DNA → 成环 → 滚环扩增 → 形成DNA纳米球(DNB)
基因组DNA首先经过片段化处理,末端修复后再加上接头序列,分离出单股DNA后并环化形成单链环状DNA。环装DNA在DNA聚合酶的作用下绕着DNA环不停地转圈,复制出的上百份拷贝都在一股新DNA上,就像一股毛线卷成了毛线团一样,最后形成一团DNA纳米球(DNB, DNA Nano Ball),这一步即为滚环扩增技术(Rolling circle amplification, RCA),可将单链环状DNA扩增2-3个数量级。

图13纳米球DNB形成原理
3. DNA序列识别
DNA纳米球附着芯片 → 组合探针锚定连接法测序
DNB纳米球经过装载技术固定在阵列化(Patterned Array)的硅芯片上,芯片每个位点的蛋白质上自动附着上去一个DNB纳米球并且不会发生堆叠。接下来就是测序过程了,华大测序仪采用了联合探针锚定聚合(combinatorial Probe Anchor Synthesis,cPAS)技术进行测序,首先DNA分子锚和荧光探针在DNB上进行聚合,随后高分辨率成像系统对光信号进行采集,光信号经过数字化处理后即可获得待测序列。

图14 组合探针锚定连接法测序流程
4. 分析
碱基读取 → 数据比对和组装 → 基因组 → 结果分析
5. 技术优势
与其他二代测序技术相比较,DNB测序技术具有以下几个优势:
(1)DNB通过增加待测DNA的拷贝数而增强了信号强度,从而提高测序准确度;
(2)不同于PCR指数扩增,滚环扩增技术的扩增错误不会累积;
(3)DNB与芯片上活化位点的大小相同,每个位点只固定一个DNB,保证信号点之间不产生相互干扰;
(4)阵列化测序芯片和DNB测序技术的结合,使得成像系统像素和测序芯片的面积得到最大化利用。
华大基因测序仪测序过程及原理视频集锦:
5.高通量测序模版克隆方法简介
模板放大即需要把待测序的核酸扩增,如下图所示,NGS技术模板扩增主要有以下四种策略:
(1)乳液PCR【454(Roche),SOLiD(Thermo Fisher),GeneReader(Qiagen),Ion Torrent(Thermo Fisher)】
在乳液PCR,片段DNA模板与dNTP、引物和DNA聚合酶包在一个油滴中。在凝胶中进行PCR扩增,最后得到成千上万份相同的DNA序列。
(2)固相桥式扩增【Illumina】
片段DNA分散到Flow cell上,与固定的引物结合,进行桥式扩增,从而形成很多DNA簇。
(3)固相的模板移位【SOLiD Wildfire(Thermo Fisher)】
片段DNA与固定的引物结合,PCR扩增延长引物得到第二天链。然后部分变性,使得自由端可以与邻近的引物结合,再次扩增,起到放大的效果。
6.不同高通量测序平台测序策略介绍
测序策略包含两种:边连接边测序(sequencing by ligation, SBL)以及边合成边测序(sequencing by synthesis, SBS)。
(1)边连接边测序的测序原理(SBL)——SOLiDComplete Genomics
简单说,SBL测序就是用1-2个已知碱基标记的探针与目标DNA杂交,然后再与下一个标记的探针连接,检测标记探针的信号,从而知道目标DNA的序列信息。
SOLiD的全称是Sequencing by Oligo Ligation Detection,即寡聚物连接检测测序,其基本原理是通过荧光标记的8碱基单链DNA探针与模板配对连接,发出不同的荧光信号,从而读取目标序列的碱基排列顺序。
CG的测序原理叫组合探针锚定连接(cPAL),利用四种不同颜色标记的探针去读取接头附近的碱基,探针能够与DNA片段结合,T4 DNA连接酶连接探针和anchor,使探针稳定结合,从该探针携带的荧光基团的颜色为判断出该位置是何种碱基。当一轮反应结束后,去除anchor-prob产物,重复上一轮步骤测序下一个碱基。

图15 边连接边测序的测序原理
(2)边合成边测序的测序原理(SBS)—— Qiagen GeneReader,Illumina,Roche454, Ion Torrent
SBS这个术语是用来描述依赖DNA聚合酶来测序的方法,但是SBS方法又可以分为循环可逆终止(CRT)和单碱基添加(SNA)。
虽然Qiagen公司的GeneReader也是采用CRT的测序原理,但我们熟知的还是Illumina的CRT测序原理。四种dNTP被不同的荧光标记,每个循环就结合一个互补的碱基,拍四次照,四个照片重合,出现哪种荧光标记就可以确定是哪个碱基。反应之后荧光基团会被切除,这样就露出了3’羟基基团(-OH),可以与下一个碱基连接。

图16 边合成边测序的测序原理合
另一种SBS测序方法叫单碱基添加(SNA),454焦磷酸测序和Ion Torrent都属于这种测序原理。SNA的方法依赖单个信号来标记每个测序的碱基。因为它不能终止反应,所以每次只能允许进一种碱基来防止继续延长。这样要是单碱基重复就会继续读取。454是第一台NGS测序仪,它的SNA系统是含有特定引物的珠子连同酶混合物一起进入Pico Titer Plate,当有一个碱基连入DNA链,就会产生一个生物荧光信号,通过相机捕获。
7.高通量测序的优缺点
一般芯片只能检测已知位点,而二代测序则可以帮助科学家们发现许多未知的新的基因和位点,并且具有通量高,速度快、应用范围广泛的特点。
虽然NGS有其优势,但其本身存在一定的技术缺陷,例如只能读取几十个到几百个碱基长度的序列,这意味着需要更严格复杂的序列拼接。测序结束后可以获得海量的数据量,但是其质量却有待提高(有报道,NGS 在序列拼接过程中,错误率在 0.1-15%范围内)。除此以外,二代测序建库过程中存在打断长片段DNA环节,建库涉及到PCR扩增,会出现系统偏好性等问题。
8.高通量测序中常见专业术语(1)测序数据相关专业术语
O Fragments:就是打成的片段,而测序测的就是这些fragments, 测出来的结果就是reads,又可以分为单端测序和双端测序,单端测序的话,只是从fragments的一端测序,测多长read就多长,双端测序就是从一个fragments的两端测,就会得出两个reads。
O Read: 高通量测序时,在芯片上的每个反应,会读出一条序列,是比较短的,测序的最小单位,叫read,它们是原始数据。
O Contig: 拼接软件基于reads之间的重叠(overlap)区,拼接获得的序列称为Contig(重叠群)。 (由reads通过对overlap区域拼接组装成的没有gap的序列段)
O Contig N50:Reads拼接后会获得一些不同长度的Contigs。将所有的Contig长度相加,能获得一个Contig总长度。然后将所有的Contigs按照从长到短进行排序,如获得Contig 1,Contig 2,Contig 3..."""Contig 25。将Contig按照这个顺序依次相加,当相加的长度达到Contig总长度的一半时,最后一个加上的Contig长度即为Contig N50。可以作为基因组拼接的结果好坏的一个判断标准。
O Scaffold:多个contigs通过片段重叠,组成一个更长的scaffold,基因组de novo测序,通过reads拼接获得Contigs后,往往还需要构建454 Paired-end库或Illumina Mate-pair库,以获得一定大小片段(如3Kb、6Kb、10Kb、20Kb)两端的序列。基于这些序列,可以确定一些Contig之间的顺序关系,这些先后顺序已知的Contigs组成Scaffold。
O Scaffold N50:参照Contig N50理解。
O 测序的覆盖度(coverage):是指测序获得的序列占整个基因组的比例,也可理解为对目的基因的覆盖程度。
O 测序深度(Sequencing Depth):测序得到的碱基总量(bp)与基因组大小(Genome)的比值,它是评价测序量的指标之一。假设一个基因大小为2M,测序深度为10X,那么获得的总数据量为20M。也可以理解为被测基因组上单个碱基被测序的平均次数。
O Q20(Q30) >xx% 则表示质量值大于等于20或30的碱基所占百分比。例如,一共测了1G的数据量,其中有0.9G的碱基质量值大于或等于20,那么Q20则为90%。
O 测序数据量=基因组大小(所测范围大小)×测序深度 或者测序reads 数 × reads 长度(读长)
O E期望值(E-value):表明在随机的情况下,其它序列与目标序列相似度要大于这条显示的序列的可能性。所以它的分值越低越好。
(2)数据库相关专业术语
O COG:Cluster of Orthologous Groups,蛋白质直系同源数据库,是对基因产物进行直系同源分类的数据库,每个COG蛋白都被假定来自祖先蛋白,COG数据库是基于细菌、藻类、真核生物具有完整基因组的编码蛋白、系统进化关系进行构建的。COG 分为两类,一类是原核生物的,称为 COG 数据库;另一类是真核生物,称为 KOG 数据库。
O Nr:Non-redundant protein database,非冗余蛋白数据库
O SwissProt:SwissProt protein database,蛋白质序列数据库
O Pfam:Protein families database,蛋白质家族数据库
O GO:Gene Ontology,基因本体论数据库
O KEGG:Kyoto Encyclopedia of Genes and Genomes,东京基因与基金组百科全书,是系统分析基因产物在细胞中的代谢途径以及这些基因产物的功能的数据库,用KEGG可以进一步研究基因在生物学上的复杂行为。
(3)数据分析相关专业术语
O SNP:单核苷酸多态性,个体间基因组DNA序列同一位置单个核苷酸变异(替代、插入或缺失)所引起的多态性。是研究人类家族和动植物品系遗传变异的重要依据。
O SSR:simple sequence repeat,简单重复序列,又称微卫星序列,是最具长度变异的基因组序列之一。
O SNV: 相对于正常组织,癌症中特异的单核苷酸变异是一种体细胞突变(somatic mutation),称做SNV。
O INDEL:基因组上小片段(50bp)的插入或缺失,形同SNP/SNV。
O CNV:copy number variation,拷贝数变异,基因组拷贝数变异是基因组变异的一种形式,通常使基因组中大片段的DNA形成非正常的拷贝数量。这个小编认为可以类比染色体变异。
O SV:structure variation ,基因组结构变异,主要包括染色体大片段的插入和缺失(引起CNV的变化),染色体内部的某块区域发生翻转颠换,两条染色体之间发生重组(inter-chromosome trans-location)等。一般SV的展示利用Circos 软件。
O SD区域:指串联重复,由序列相近的一些DNA片段串联组成。在人类染色体Y和22号染色体上,有很大的SD序列。
O RPKM:Reads Per Kilobases per Millionreads,代表每百万reads中来自于某基因每千碱基长度的reads数,用于表示基因的表达量或丰富度。在衡量基因表达量时,若是单纯以map到的read数来计算基因的表达量,在统计上是一件相当不合理的事,因为在随机抽样的情况下,序列较长的基因被抽到的机率本来就会比序列短的基因较高,如此一来,序列长的基因永远会被认为表达量较高,而错估基因真正的表达量,所以Ali Mortazavi等人在2008年提出以RPKM在估计基因的表达量。其计算公式为:
O FPKM:将RPKM中的read换成freagment来理解,也是用于表示基因的表达量或丰富度。如果是single-end测序,二者FPKM和RPKM是一致的。如果是pair-end测序,每个fragments会有两个reads,FPKM只计算两个reads能比对到同一个转录本的fragments数量,而RPKM计算的是可以比对到转录本的reads数量。O
O 基因组注释(Genomeannotation) :是利用生物信息(bioinformation)学方法和工具,对基因组所有基因的生物学功能进行高通量注释,是当前功能基因组学(functional genomics)研究的一个热点。基因组注释的研究内容包括基因识别和基因功能注释两个方面。基因识别的核心是确定全基因组序列中所有基因的确切位置。
(4)应用领域相关专业术语
O de novo测序: 没有参考基因组的测序,也称为从头测序,它不需要任何现有的序列资料就可以对某个物种进行测序,利用生物信息学分析手段对序列进行拼接,组装,从而获得该物种的基因组图谱。
O 基因组重测序: 全基因组重测序是对基因组序列已知的个体进行基因组测序,并在个体或群体水平上进行差异性分析的方法。
O ChIP-Seq:将ChIP与第二代测序技术相结合的ChIP-Seq技术,通过染色质免疫共沉淀技术(ChIP)特异性地富集目的蛋白结合的DNA片段,并对其进行纯化与文库构建,然后对富集得到的DNA片段进行高通量测序。通过基因组定位,获得全基因组范围内与组蛋白、转录因子等互作的DNA区段信息。
O RIP-seq: 与ChIP-Seq类似,运用针对目标蛋白的抗体把相应的RNA-蛋白复合物沉淀下来,然后经过分离纯化就可以对结合在复合物上的RNA进行测序分析。
O metagenomic宏基因组: 直接从环境样本中提取的基因组遗传物质,研究对象是整个微生物群落。
9. 高通量测序的应用领域
测序技术推进科学研究的发展。随着第二代测序技术的迅猛发展,科学界也开始越来越多地应用第二代测序技术来解决生物学问题。在基因组水平上对还没有参考序列的物种进行从头测序(de novo sequencing),获得该物种的参考序列,为后续研究和分子育种奠定基础;对有参考序列的物种,进行全基因组重测序(resequencing),在全基因组水平上扫描并检测突变位点,发现个体差异的分子基础;还可以在宏基因组水平进行微生物多样性及功能鉴定等。在转录组水平上进行全转录组测序(whole transcriptome resequencing),从而开展可变剪接、编码序列单核苷酸多态性(cSNP)等研究;或者进行小分子RNA测序(small RNAsequencing),通过分离特定大小的RNA分子进行测序,从而发现新的microRNA分子等。在表观组水平上,与染色质免疫共沉淀(ChIP)和甲基化DNA免疫共沉淀(MeDIP)技术相结合,从而检测出与特定转录因子结合的DNA区域和基因组上的甲基化位点等。此外,还有基于二代测序结合微阵列技术而衍生出来目标序列捕获测序技术(Targeted Resequencing),如全外显子组捕获测序等。
目前,高通量测序除了广泛应用于科学研究领域,已经慢慢开始渗透到临床研究,如疾病候选基因筛查,无创产前诊断、肿瘤临床诊断、遗传性疾病检测等。随着技术越来越成熟,高通量测序技术将设计人类研究的各个领域,并发挥重要的作用,

图17 高通量测序的应用
以上就是高通量测序原理及其发展简介全部内容;搜索关键词()还能找到更多精彩内容。